This repository contains the code for implementing and running the pipeline described in the paper “Retrieve, Merge, Predict: Augmenting Tables with Data Lakes”.
It also includes a series of additional ancillary scripts used for preparing the plots and carrying out additional measurements over the different steps.
A simple example
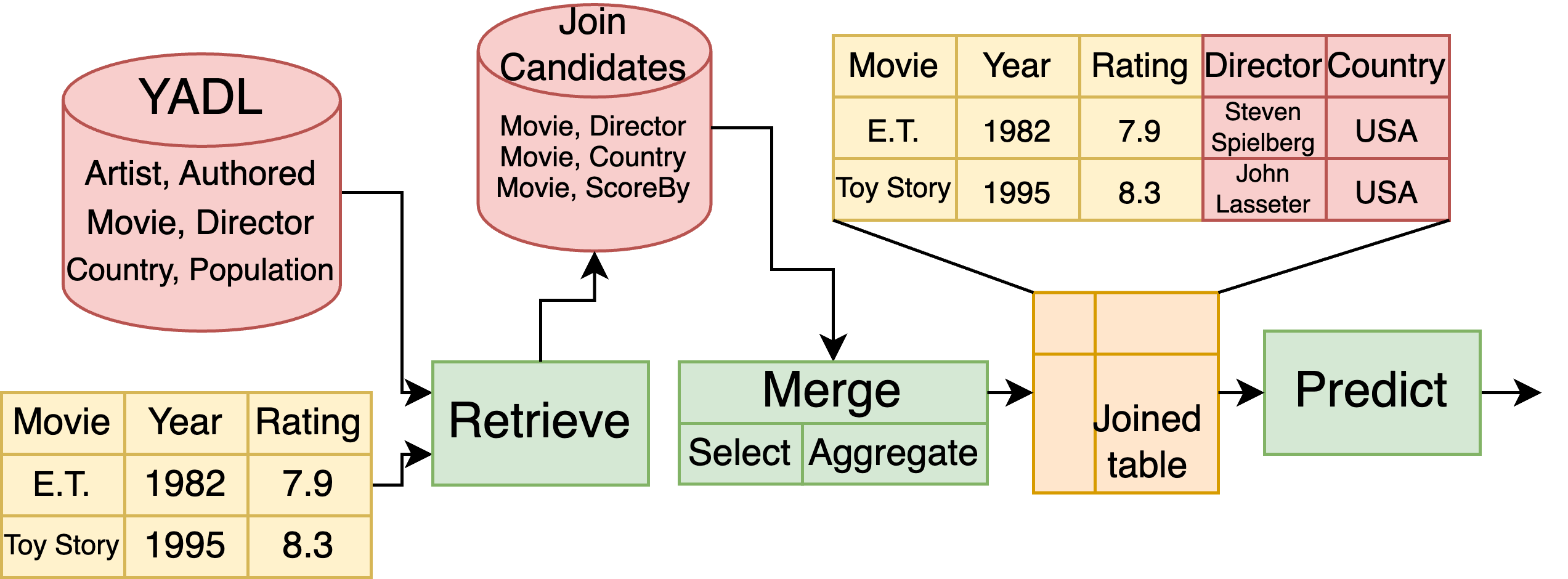
Alice is working on a base table that contains information about movies. She has also access to a data lake, or a collection of other tables on all sorts of subjects.
She is looking for a way to predict the ranking of a movie based on as much information as possible. Given that she has access to a data lake, she would like to extract some of the stored information to improve the performance of her model.
The problem is that, while the information she needs may indeed be available, it is mixed with a huge amount of unrelated data.
Thus, Alice’s problem is: “how can I find tables that are relevant to my problem? how do I combine them with my base table?”
This toy example was our starting point for creating the our pipeline, where we illustrate the various step that Alice may need in order to predict the movie rating.
We highlight three operations that must be performed to go from Alice’s base table, to an integrated table on which she can train a ML model:
- Retrieve the join candidates, i.e., extract from the data lake those tables that can be joined on the base table.
- Merge the candidates with the base table in the most effective way possible.
- Predict the result using a ML model.
We design and build YADL, a synthetic data lake based on the YAGO3 knowledge base to use as our benchmarking data lake. We make the variants we used in the paper available on Zenodo.
Running the code
Code repositories The repository containing the pipeline and the code required to run the experiments can be found in the pipeline repository. The code for preparing the YADL variants can be found in the preparation repository.
Retrieve the code either by cloning the main repository:
git clone https://github.com/rcap107/retrieve-merge-predict.git
or by downloading the latest release from tags.
Base tables
The base tables used for the experiments are available in the pipeline repository, in folder data/source_tables. More information is reported in Dataset info.
Data lakes The data lakes used for our experiments are stored on Zenodo. Follow the instructions in Downloading the data lakes to prepare them.
Requirements
The repository relies heavily on the parquet format [ref], and will expect all tables (both source tables, and data lake
tables) to be stored in parquet format. Please convert your data to parquet before working on the pipeline.
We recommend to use conda environments to fetch the required packages. File environment.yaml contains the
required dependencies and allows to create directly a conda environment:
conda env create --file=environment.yaml
conda activate bench
Then, from within the bench environment install the remaining dependencies with pip:
pip install -r requirements.txt
Preparation of the testing environment Running the experiments requires some preparation to build the data structures that are required by the retrieval step. This is reported in Preparing the environment.
Pipeline execution The page Running the pipeline contains the information required for preparing configurations, running the pipeline, recovering from a pipeline crash, and exploring the profiling results.
Make sure that the preparation has been run properly, since the pipeline is relying on data structures that are assumed to have been prepared during the previous step.
Additional scripts This repository contains various scripts for plotting results and measuring in detail specific sections of the pipeline. We detail their functions in this page.