Embeddings to Bring Background Information
For data science on common entities, such as cities, companies, famous people… augmenting the data at hand with information assembled from external sources may be key.

For instance, estimating housing prices benefits from background information on the location: the population density, the average income… This information is present in external sources such as wikipedia. But assembling features that summarize the information is tedious manual work, which we seek to replace.
We provide readily-computed vectorial representations of entities (e.g. cities) that capture the information that can be aggregated across wikipedia.
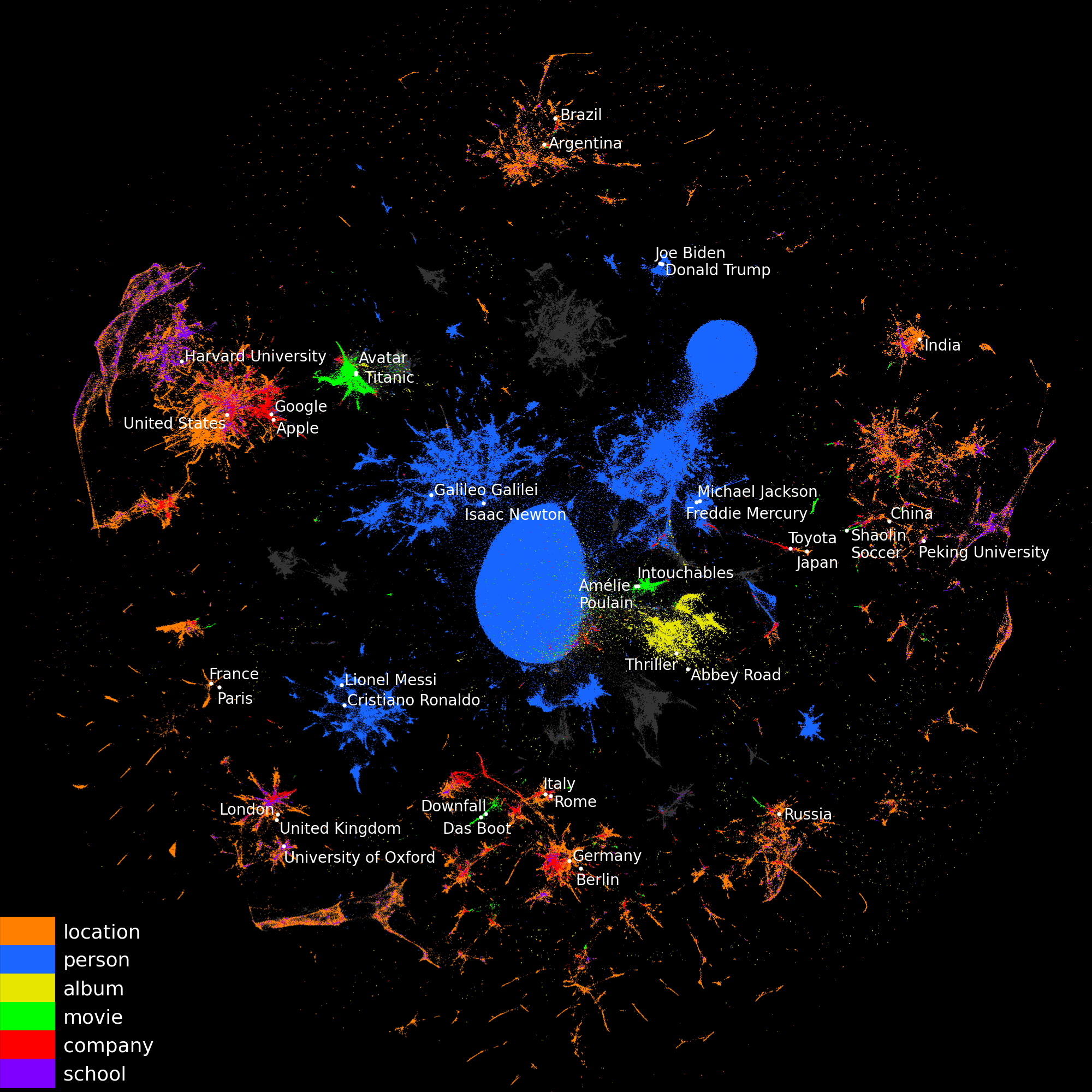 2D visualization of entity embeddings, colored by
their types. UMAP was
used to reduce their dimension from 200 to 2.
2D visualization of entity embeddings, colored by
their types. UMAP was
used to reduce their dimension from 200 to 2.
Downloading the embeddings
We give different tables for the embeddings of entities of various types (under a Creative Commons Attribution 4.0 International License):
We also provide tables with embeddings for all entities (5.7 million), as well as their types:
How are these embeddings built?
The academic publication gives the full details; below we provide a short summary.
We represent the relational data on the entities as a graph and adapt graph-embedding methods to create feature vectors for each entity. We show that two technical ingredients are crucial: modeling well the different relationships between entities, and capturing numerical attributes. For this, we leverage knowledge graph embedding methods. Although they were primarily designed for graph completion purposes, we show that they can serve as powerful feature extractors. However, they only model discrete entities, while creating good feature vectors from relational data also requires capturing numerical attributes. We thus introduce KEN (Knowledge Embedding with Numbers), a module that extends knowledge graph embedding models to numerical values.
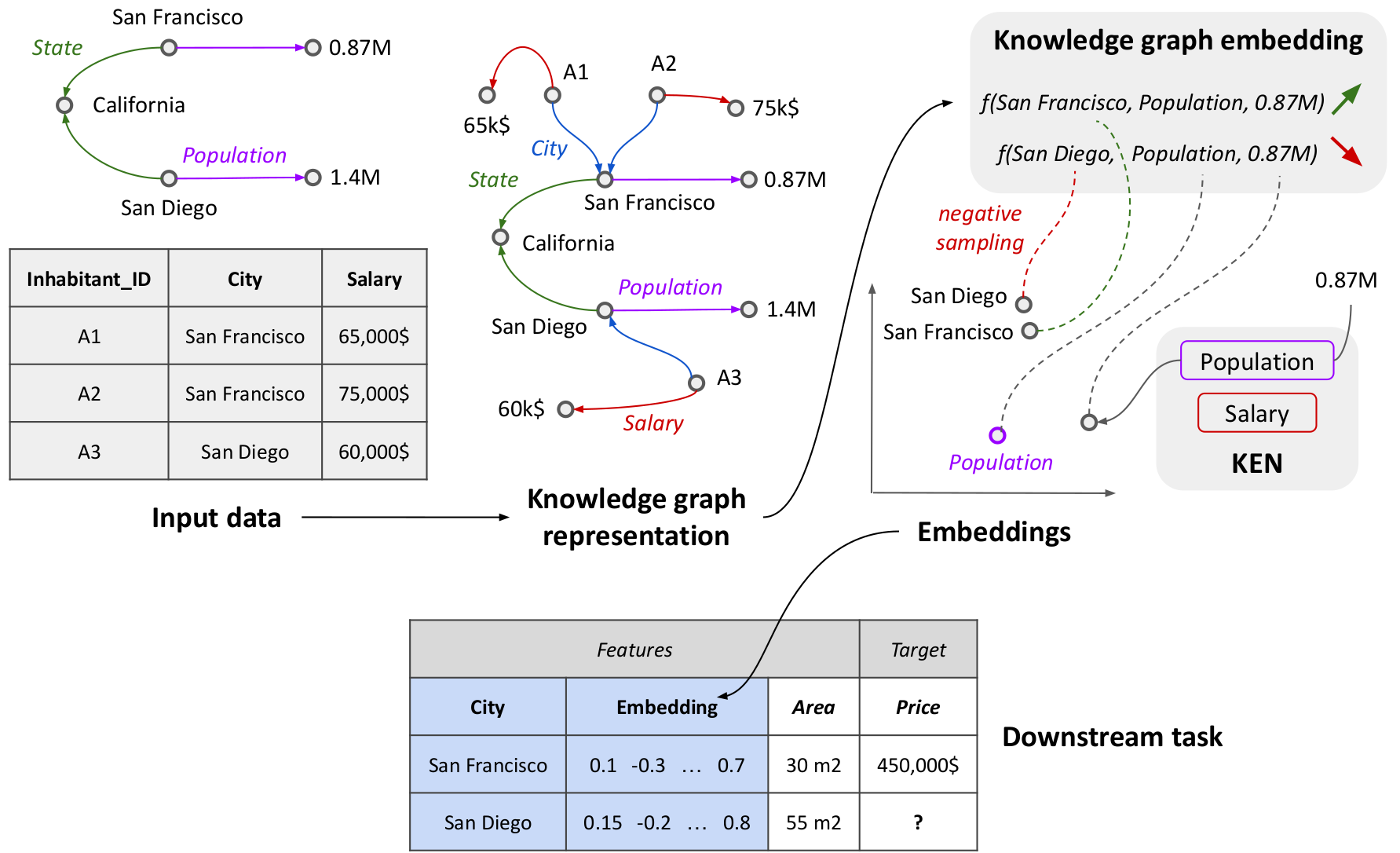 Our embedding pipeline for feature enrichment.
Our embedding pipeline for feature enrichment.
We thoroughly evaluate approaches to enrich features with background information on 7 prediction tasks. We show that a good embedding model coupled with KEN can perform better than manually handcrafted features, while requiring much less human effort. It is also competitive with combinatorial feature engineering methods, but is much more scalable. Our approach can be applied to huge databases, creating general-purpose feature vectors reusable in various downstream tasks.
Embedding the data in Wikipedia
To build embeddings that capture the information from Wikipedia we leverage YAGO3, a large knowledge base derived from Wikipedia, and apply our embedding pipeline to generate vectors for many entities.
YAGO3 and its embeddings
YAGO3 is a large knowledge base derived from Wikipedia in multiple languages and other sources. It represents information about various entities (people, cities, companies…) in the form of a knowledge graph, i.e. a set of triples (head, relation, tail), such as (Paris, locatedIn, France). Overall, our 2022 version of YAGO3 contains 5.7 million entities, described by 22.6 million triples (including 7.8 million with numerical values, such as city populations or GPS coordinates).
We learn 200-dimensional vectors for these entities, using as knowledge-graph embedding model MuRE (Balažević et al., 2019), which we combine with KEN to leverage numerical attributes.